前言
神经网络在图像、语音识别等领域使用越来越广泛,大部分实时性要求不高的服务都可以部署在云上,然而还是有不少模型需要在计算能力有限的可移动设备上快速运行,如人脸解锁、拍照视频的实时处理等。
一般训练的模型采用的都是32位浮点数,考虑到大部分的模型都具有比较强的抗噪能力,即即使输入受到了一定的干扰,最后预测出正确的结果,所以在手机等智能设备上,可以通过适当降低精度而基本影响结果的正确率,来达到加速计算或降低功耗的目的,例如GPU可以使用half计算、DSP上可以使用int8计算。
最近刚好了解了一下tensorflow和nnlib的一些量化的实现,踩过一些坑,在此总结和分享一下。
简介
什么是量化
引用百度百科上的一句话:
在数字信号处理领域,量化指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。
对神经网络的量化,也就是将神经网络中大部分op的浮点权重值转换为定点整数表示,同时将op替换成可以执行类似的定点整数运算的op。于是网络中大部分的浮点运算,都能使用定点整数计算替代。
为什么要量化
-
提高计算速度&降低功耗。将32位浮点数计算转换成8位定点计算,在一些支持SIMD的平台上能大大提速,例如高通的DSP支持一条指令同时计算128字节的向量。
-
减少存储消耗。将神经网络每层的32位浮点数权重,转换为8位定点+最小最大值的存储方式,模型的大小能减少为原来的约25%。
神经网络量化的实现
-
神经网络对量化的实现需要把常见操作(卷积,矩阵乘法,激活函数,池化,拼接等)转换为等价的8位整数版本的操作,然后在操作的前后分别加上quantize和dequantize操作,quantize操作将input从浮点数转换成8 位整数,dequantize操作把output从8 位整数转回浮点数。以Relu为例:
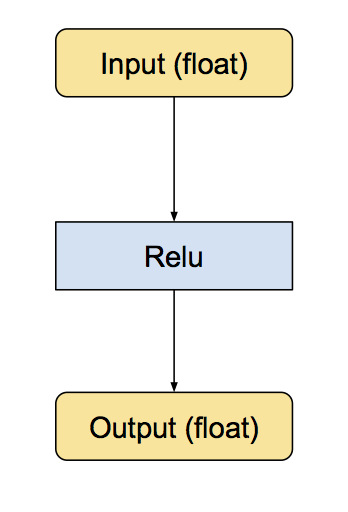
经过转换后,新的子图如下:
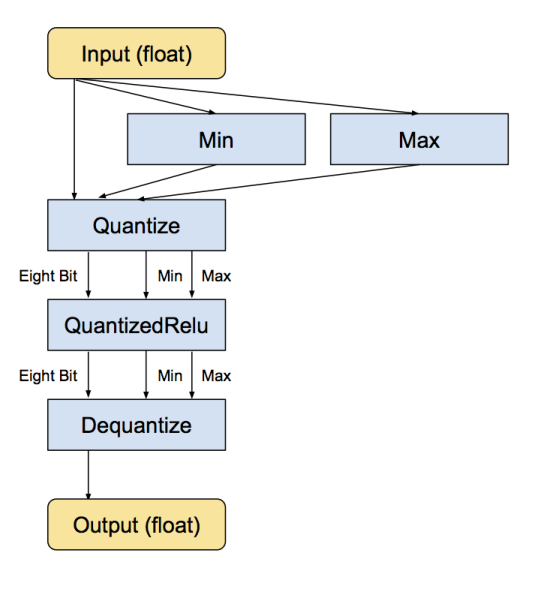
-
连续的dequantize和quantize操作可以互相抵消,如图所示:
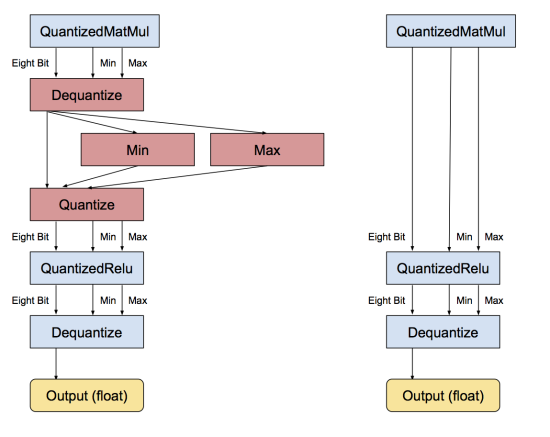
量化操作的实现
量化操作需要将一组float输入转换成uint8(0~255),最直观的想法就是先求出这组输入的最小值min和最大值max,然后对每个输入数据可以用
q = (x - min) / (max - min) * 255
求出其量化值。反之,也可以用
x = q * (max - min) / 255 + min
实现反量化操作。
量化后引入的量化误差为(max - min)/255.
量化过程这里有一个坑,那就是真实值0.0的量化误差,一般来说需要保证输入0.0值被精确地量化成一个整数qzero表示,如果量化值qzero所表示的值和真实值0.0之间有一定误差,那么对一些操作会有比较大的影响,比如卷积或者pooling层做padding时需要在边缘补0,Relu层需要截断小于0的输入。
关于量化操作,tensorflow和nnlib的策略不太一样。
-
tensorflow:
分有符号输入和无符号输入两种情况。
- 有符号输入:调整min和max,max=MAX(-min, max), min = -max, 这样可以使得范围是对称的,[min, max]被量化至[-127, 127]
- 无符号输入:令min=0,然后将[0, max]量化至[0, 255]
以上两种情况下,都能保证输入的0.0值能刚好被量化成0.
-
nnlib:
不区分是否为有符号,统一量化到0~255。下面这部分源码是为了调整min和max的值,使得0.0被量化后的误差小于2^-14.
static inline void quantize_adjust_range(float *out_min, float *out_max, float *out_stepsize, float *out_recip_stepsize, float in_min, float in_max)
{
// 确保0被包含在[min, max]
float minval = fminf(0.0f,in_min);
float maxval = fmaxf(0.0f,in_max);
float range = fmaxf(0.0001f,maxval-minval);
float recip_stepsize = 255.0f/range;
// move either min, or max, as little as possible,
// so that the 'zero' point -min *255/range is an integer.
// if minval == 0 this is already true.
if( minval < 0.0f ){
float z = - minval *recip_stepsize; // current 'zero point'
float zi = floorf(z); // integer part, >=0
float zf = z - zi;
// if within 2^-14 of an integer, call it close enough
if( zf > 6.1035156e-05f && zf < 0.999938965f){
// choose which end to move
// if zi <= 0 or >= 254, the decision is based on that only (to
// avoid divide by 0) otherwise choose based on which can be moved
// the least.
if( zi > 0.0f && ( zi > 253.0f || (zf-1.0f)*minval>= zf*maxval )) {
// increase max, change z to zi
range = -255.0f*minval/zi;
maxval = minval+ range;
}else{
// decrease min; change z to zi+1
minval = maxval*(zi+1.0f)/(zi-254.0f);
range = maxval-minval;
}
// recalc range
recip_stepsize = 255.0f/range;
}
}
*out_min = minval;
*out_max = maxval;
*out_stepsize = flt_div_255(range);
*out_recip_stepsize = recip_stepsize;
}
参考链接
- tensorflow quantization
- What I’ve learned about neural network quantization
- https://github.com/tensorflow/tensorflow
- https://source.codeaurora.org/quic/hexagon_nn/nnlib